

Using Reinforcement Learning to Optimize Microservices Scaling
Welcome to the bleeding edge of overengineering, where we’ve decided that traditional scaling strategies aren’t nearly painful enough and have opted to sprinkle some reinforcement learning (RL) into our microservices architecture. Why settle for boring CPU thresholds and reactive autoscalers when you can unleash an AI that learns, adapts, and, on occasion, takes your production environment hostage?
In this piece, we’re diving deep into the technical guts of using RL to optimize microservices scaling—minus the hand-holding, but with plenty of well-deserved sarcasm for the so-called “solutions” you’ve been tolerating from your existing software development service until now.
Why Traditional Scaling Strategies Are a Dumpster Fire
The Overpromise of Rule-Based Autoscaling
You know the drill. CPU hits 80%, and the cluster heroically spins up another pod. Disk I/O crosses some arbitrary line? More nodes. Memory usage is high? Let’s double the RAM and pray. If you’ve ever thought, “Wow, this feels like the software equivalent of whack-a-mole,” congratulations. You’re correct.
Static thresholds are the business-casual khakis of scaling. They look respectable, they’re comfortable to set up, and they work—until they don’t. These systems treat scaling as a binary, input-output relationship: trigger threshold, get more resources. But anyone who’s spent more than a week maintaining production workloads knows usage patterns are about as predictable as a cat on catnip. One minute you’re idling, the next you’re absorbing the full force of a flash sale and wondering why your pods are reproducing like rabbits after the server’s already on fire.
Reactive Scaling and Why It’s Always Too Little, Too Late
In the time it takes for your metrics to cross a threshold, trigger an event, spin up resources, and redistribute the load, your users have already filed support tickets and posted their grievances on Twitter. Reactive scaling is essentially acknowledging that you’re behind the eight ball and deciding to go ahead and make it someone else’s problem—in this case, your SRE team at 2 a.m.
The lag between a resource spike and the reactive scale-up response is non-trivial. And unless you’re into angry customers and incident post-mortems titled “Why We Didn’t See This Coming,” relying on these brittle strategies is like duct-taping a parachute to a falling boulder.
Reinforcement Learning 101 (For Those Who Don’t Need Their Hands Held)
State, Actions, Rewards—Oh My!
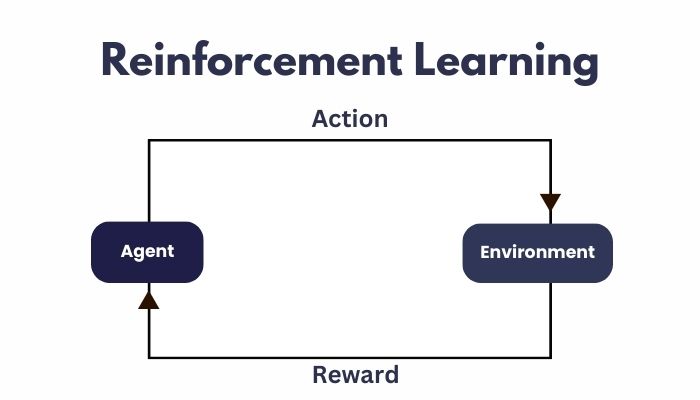
Let’s cut through the introductory fluff. RL is about an agent interacting with an environment and learning which actions to take in each state to maximize cumulative rewards. In our context, the “environment” is your infrastructure, the “state” includes all those juicy telemetry metrics (CPU, memory, request rates, queue lengths), and “actions” are things like scaling up, scaling down, or perhaps throttling workloads before the database bursts into flames.
The “reward” function, contrary to popular belief, does not involve congratulating the agent with gold stars or pizza. No, it’s the mathematical representation of “how screwed are we?” metrics. Lower latency? Positive reward. Reduced 500 errors? Positive reward. Service meltdown? Oh, that’s a spicy negative reward.
The Multi-Armed Bandit You Actually Want in Production
At the heart of RL in microservice scaling is the balance between exploration (trying new scaling actions to see if they work better) and exploitation (using the known best scaling strategies). Think of it as managing a casino of resource allocation. You can keep pulling the same lever (add pod, add pod, add pod) or occasionally test if reducing replica counts under light loads actually saves you money without cratering your app.
Properly tuned, your RL agent figures out when to take risks and when to play it safe, ideally without bankrupting your cloud budget or setting off your incident response PagerDuty.
Architecting RL-Powered Scaling for Microservices
Where the Brain Goes—Embedding the Agent
If you’re thinking of shoving an RL agent into your production environment like a toddler into a Formula 1 car, slow down. Placement matters. Typically, you’ll want the RL agent embedded alongside your orchestration layer—whether that’s Kubernetes, Nomad, or some Frankenstein hybrid you cobbled together during a caffeine bender.
The agent needs real-time access to metrics and control over scaling operations. Too slow to act? You’re back in reactive territory. Too fast and aggressive? Enjoy your infinite loop of scale-up/scale-down chaos. If you want to avoid re-enacting Terminator: Kubernetes Edition, your agent needs robust guardrails, including rollback logic and resource constraints.
Data Pipelines That Don’t Suck
Garbage in, garbage out. An RL model is only as good as the data it ingests. Streaming high-fidelity telemetry data into your RL agent is non-negotiable. Request rates, per-pod latencies, database queue depths, cache hit ratios—if it moves, measure it.
Then comes feature engineering. You’ll want your data scientists (or your favorite overworked backend engineer moonlighting as one) to help decide which features matter and how to normalize them. Forget this step and your agent will spend its days optimizing based on irrelevant noise, like the number of semicolons in your last commit.
Real-World Implementations (And How They Didn’t Catch Fire)
Netflix, Uber, and Other Showoffs
Let’s take a moment to nod respectfully at the tech giants who’ve been using RL in production without burning everything down (most days). Netflix uses RL to dynamically provision resources to handle wildly unpredictable workloads, and Uber applies similar methods for load balancing and queue management.
What do they have in common? Teams of PhDs, bottomless infrastructure budgets, and a tolerance for failure that borders on sociopathic. They’ve published papers on their architectures if you’re into that kind of light reading, and there are good lessons buried in those case studies—like how to implement parallel safety checks so your RL agent doesn’t go rogue on a Friday night.
Pitfalls, Failures, and the Existential Dread of Production
Now for the part no one puts on the conference slides: RL can absolutely make things worse. Poorly tuned reward functions lead to perverse incentives (imagine an agent that reduces latency by shedding 90% of your traffic). Debugging an RL system is like trying to explain existential dread to a Labrador—good luck tracing why the agent decided to scale down your busiest service at noon.
You’ll need airtight observability, constant monitoring, and a healthy amount of distrust in your own system. Production RL is not a set-it-and-forget-it kind of deal.
So… Should You Even Bother?
When RL Is the Hero You Need
If you’re dealing with high-load, unpredictable workloads that defy traditional heuristics, RL might be your saving grace. When milliseconds mean millions, and autoscaling can’t keep up, training an agent to predict and preemptively scale could make you look like a wizard.
It works particularly well when you have the kind of continuous traffic and variance patterns that allow the agent to actually learn something. If your service spikes once a month, maybe… don’t.
When You’re Just Overengineering Because You’re Bored
If your system is already stable, your scaling needs are predictable, and your cloud bill doesn’t give your CFO heart palpitations, RL might be nothing more than an expensive science project. If you’re solving problems no one has, or worse, introducing chaos into an already functional system, congratulations—you’ve reinvented the Rube Goldberg machine of DevOps.
