

Top 7 Web Scraping Tools for Data Extraction
Web scraping, also known as ‘web harvesting’ or ‘screen scraping’, is a way of extracting data from websites in an automated and structured manner. It can be used to collect valuable information on product pricing and reviews, customer sentiment analysis, and competitor monitoring, across any industry that has some sort of online presence.
This is becoming increasingly important for businesses looking for insights into the ever-changing market trends. Individuals too are leveraging web scrapers to automate mundane tasks such as price comparison when shopping online – essentially saving time by automating repetitive workflows!
1. Beautiful Soup
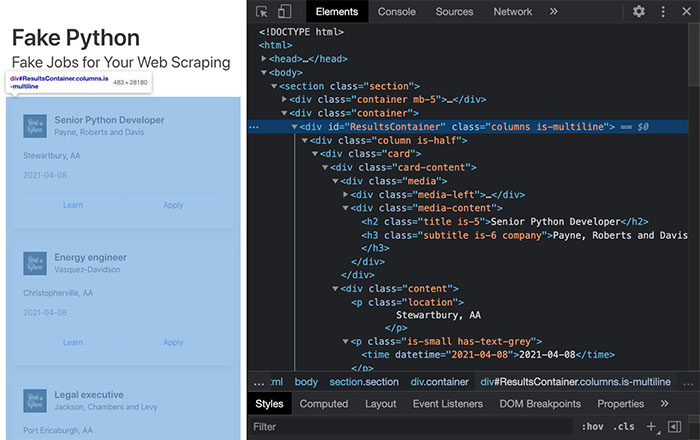
Beautiful Soup is a powerful Python library for web scraping. It provides features such as preventing packages from being downloaded more than once, high-level interface parsing HTML files and XML documents into trees of data, instantly converting complicated website information to well-organized formats like CSV or JSON, and full support for Unicode documents even in Python 2.
Implementation also has simple methods used by developers cut down time on common tasks and debug scripts that handle complex data structures easier thereby making it the best solution when you need to scrap multiple websites efficiently providing generated datasets which can open up new possibilities.
Advantages and disadvantages of using Beautiful Soup
It provides simple methods to navigate, search and modify the structured data of parsed HTML pages using syntaxes that are close to natural language processing. By making it easier to locate specific tags in an HTML page, Beautiful Soup simplifies many steps involved in basic web scraping tasks such as parsing links from anchor tags or extracting text between paragraph elements.
Advantages:
- Ease of installation/deployment (no proxy setup required)
- Rapid development
Disadvantages:
- Limited document design recognition
- Complicated instructions associated with more complex queries on larger documents requiring versions 4 and up which have fewer dependent libraries than version 3 legacy code supports.
Examples of applications and use cases
- Extracting price comparison information over different online stores
- Harvesting raw text files like PDFs and Word documents
- Creating an eCommerce pricing monitor on specific products across retailers
2. Scrapy

Scrapy is an open-source, Python framework for web scraping. It can be used to extract data from websites and turn them into structured datasets or JSON files that are easy to work with. Scrapy allows developers to create custom spiders quickly using its core components like item pipelines, downloader middlewares, and simple task queues through a straightforward API powered by Twisted asynchronous network library.
Additionally, users can take advantage of various features such as selectors support via XPath query language; a built-in logging system called Logscape; integrated request downloading technology that skips unnecessary requests when crawling pages over the same domain multiple times; sitemap downloads and crawls page source file extensions execution options (eBook formats).
These capabilities along with other popular addons applications providing the ability to scrape JS rendered elements adequately make this open source tool one of most versatile if not top choice among python specific frameworks easily accessible on the internet today.
Advantages and disadvantages of using Scrapy
Advantages:
- Detailed documentation
- Mature development community
- Efficient scheduling system
- Support for multiple languages including HTML/XML parsers as well as CSS selectors or XPath expressions
- Processing pipelining flexibility which allows you to easily integrate it with other applications or websites
- Robust crawling abilities
- Extensible architecture so new modules can be added when needed without causing disruptions in the existing codebase
Disadvantages:
- Lack scalability – only one downloader instance per worker process by default
- Relatively expensive compared short learning curve required might make non-technical users perceive scrapy’s technical complexity daunting at first glance
Examples of use cases
- Extracting price information from product catalogs mining news articles gathered from multiple sources over various intervals for sentiment analysis purposes; collecting customer reviews about products posted on websites such as Yelp or Amazon.
- Providing crawling methods that yield better results than manual techniques since Scrapy can follow links extensively with programs instead of manually copy-pasting URL endpoints.
- Finding title job postings associated with particular keywords throughout blog posts even when contained inside iFrame(s) within other sites’ framesets etc.
3. Selenium
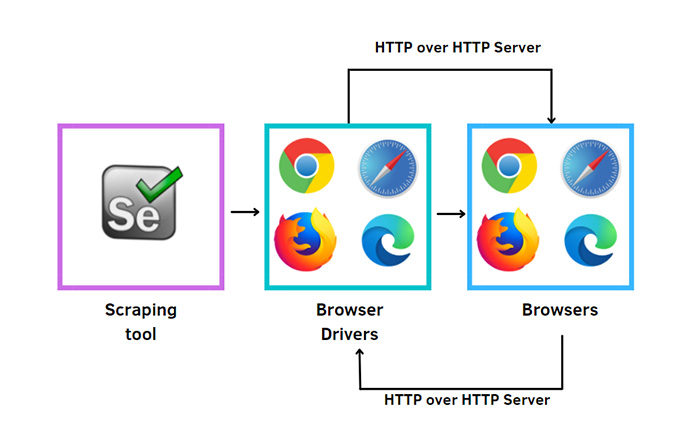
Selenium is a web testing and automation tool that can also be used for web scraping. It enables you to drive interactions with the browser, allowing users to perform tasks such as clicking on an element, inputting text into forms or even changing different logical variables of a page.
By coding in Selenium IDE (integrated development environment), developers can create automated scripts that replicate user activity when accessing websites by operating it from outside browsers instead of entering commands manually within each window. This makes it easier for testers and developers alike to automate repetitive processes more quickly than ever before!
Some additional benefits include lowered maintenance costs due creation reuse between multiple applications; reduced test suite run time via parallelization across numerous machines; improved scalability through continuous capacity expansion hidden underneath complex data ;and extensibility towards non-web application under activities like deployment and document automation or system integration simulation operations among others.
Advantages and disadvantages of using Selenium
Advantage:
It has a lot of useful features, such as allowing you to easily set up automated tests with just a few lines of code, and the ability to integrate with continuous integration systems like Jenkins.
Disadvantage:
The downside is it can require some technical know-how in order to get started; however there are extensive documentations and tutorials available online which makes learning easier if you’re willing invest time into doing so.
Furthermore, Selenium doesn’t offer access or support much data storage options unless done manually e change them frequently by updating your test scripts everytime making maintenance difficult sometimes long term & costly experience down the line when dealing on large amount info changes without “proper codes”.
Examples of applications and use cases
- Price comparison for online shopping apps; collecting financial market information about particular stocks
Aggregating restaurant reviews ratings, images, addresses and other metadata restaurants in different locales - Harvesting contact info (emails) from pages containing directories etc.
4. Octoparse
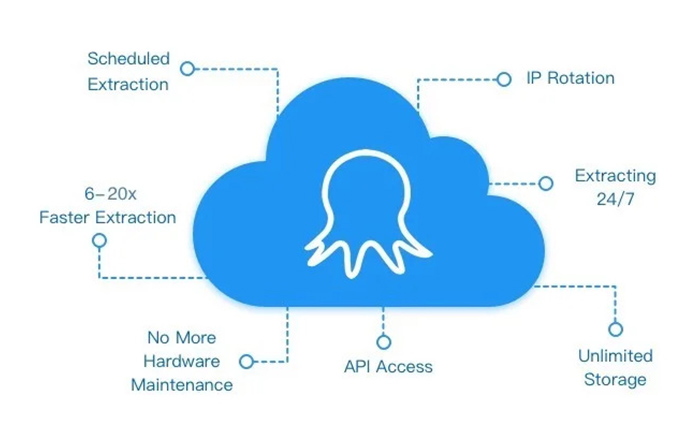
Octoparse is a cloud-based web scraping tool ideal for non-programmers. It features an easy-to-use, visual interface that enables any user, regardless of their expertise level in programming or coding knowledge quickly and efficiently collect data from websites without the need to write complex code.
Octoparse allows users to extract structured information via its point & click UI while simultaneously providing automatic maintenance updates whenever target website layout changes occur so data collection processes remain undisturbed in real-time.
This comprehensive platform provides support on over three hundred different types of browsers which include mobile phone devices, JAVA apps as well as Flash applications among many others making it perfect for businesses wanting large volumes of organized datasets right away at very minimal cost!
Advantages and disadvantages of using Octoparse
Advantages:
- User-friendly
- Easy setup with no prior coding knowledge required
- Offers detailed tutorials; customers have access to support resources (forum & email)
- Free version allows up 10K rows per extraction projects; plus there’s built-in AI recognition capability when dealing with complicated sites/pages -all this save time on manual SEO tasks.
Disadvantage:
- If you wish more than 10k row capacity then upgrades will require some outlay financially.
Examples of applications and use cases
Octoparse provides numerous plugins such as auto IP rotation (to avoid detection), saving images or videos within scraped results, etc., along with advanced features like real-time execution tracking & reports.
The applications range from monitoring product prices over different eCommerce sites; extracting news-related articles for blogging; collecting lead details for sales prediction purposes focusing solely on IT & marketing industries but there are endless possibilities in terms of usage depending upon need – one cannot explore them all.
5. ParseHub
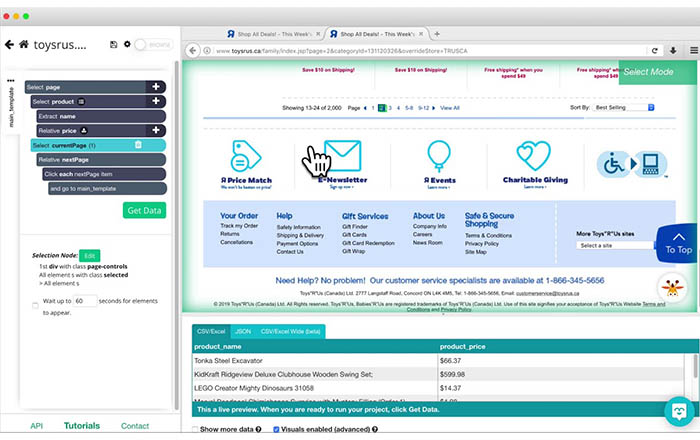
ParseHub is a visual web scraping tool designed to make data extraction from dynamic websites more accessible and efficient. With its intuitive interface, non-programmers can easily extract large amounts of structured data including comments, prices, images, and text in minutes.
It also supports automated workflow creation where scrapes run on a scheduled basis so you always have access to up-to-date information. Additionally, it provides tools for mapping results into CSV files or APIs which makes the collected data easier to work with downstream applications like analytics software or BI platforms
Advantages and disadvantages of using ParseHub
Advantages:
- Lies in its ability to extract data from multiple pages
- Dynamic content
- AJAX techniques used by many websites today.
- Provides powerful proxy rotation features which enable businesses to scrape even more efficiently on a mass scale
- Create custom sitemaps with complex logic or multiple action steps when undertaking their projects.
Disadvantages:
- Using Parsehub includes the learning curve associated with this toolset
- Users need some time working through tutorials so they can quickly become acquainted before ever attempting any kind of project implementation tasks
- Limited access levels while needing upgraded plans chargeable monthly fees if there are larger amounts of requests aimed at particular sites.
Examples of applications and use cases
Some application examples are industry price comparison for financial analysts; content aggregation & curation of news articles or blog posts; retrieving product details such as specification information and pricing on eCommerce websites.
It also has powerful features like the ability to handle AJAX calls, login forms, complex structured sites, etc which make it ideal even if there’s no access through APIs.
ParseHubscraping can be automated without writing any code into regularly scheduled tasks that run themselves every day – setting off alerts when new info appears online.
6. WebHarvy
WebHarvy is a web scraping tool that makes it easy for anyone to scrape websites with its point-and-click interface. It allows you to quickly set up your own custom scraper without the need for coding skills or knowledge in programming languages like Python, Ruby, Java, etc.
With WebHarvy’s intuitive GUI (graphical user interface), users are able to select elements off any page on the internet and can define rules on how data should be extracted from these pages into structured documents such as CSV spreadsheets using path expressions and regular expressions patterns.
In addition, Web Harvy offers features specifically designed targeted toward large-scale scrapes including proxy support and multi-threaded access which make it an ideal choice when processing hundreds of thousands of URLs at once.
Advantages and disadvantages of using WebHarvy
Advantages:
- Its visual interface makes it relatively simple for beginners to get started, with no need to write code or scripts in order to scrape content.
- Support for multiple output formats
- Auto URL typing, and navigation, configurable field extraction rules
- Image processing capabilities, etc., which can help make the process of web scraping faster and easier when compared to other tools available on the market.
Disadvantages:
- This software does not have built-in automatic proxy rotation & IP address anonymity mechanisms
- Lacks support for extracting text/content inside Javascript regions or embedded objects like PDF’s
- Requiring additional configurations before executing scrapes successfully.
- Examples of applications and use cases
- Collecting contact information (business directories)
Competitor pricing analysis/tracking - Job postings search engine spiders among others
7. Apify
Apify is a cloud-based web scraping tool that helps simplify the process of extracting data from any website. It offers an extensive platform and marketplace with various user-friendly tools to help automate complex tasks such as scheduling, building APIs, loading up configuration files, and more.
It also provides users with access to millions of ready-made components created by other developers so they can easily plug them into their own applications or deployment systems for rapid development cycles. Additionally, its powerful set of features including browser automation makes it easy for businesses to quickly carry out business intelligence processes without having in-depth technical expertise on coding languages available at hand.
Advantages and disadvantages of using Apify
Advantages:
- Ability to run scalable crawlers
- Intuitive visual interface
- Access to powerful features like IP rotation or proxy masking
- Automation workflows with JavaScript as well as task scheduling capabilities.
- Provides multiple integrations with popular services such as Slack and Trello along with detailed reports on crawling activity performance.
Disadvantage:
- Mainly around pricing since users must pay per page crawled which can become quite expensive depending on how many sites they intend to scrape.
Examples of applications and use cases
- Price monitoring websites (e.g. Amazon)
- Real estate property listings aggregators
- Media outlets that require story leads
- Job portals seeking candidates’ information
Conclusion
Web scraping is an essential tool for extracting data from websites, and there are many tools available to make this task more efficient. The top 10 web scraping tools covered in this article – Beautiful Soup, Scrapy, Selenium, Octoparse ParseHub WebHarvy Apify ContentGrabberBeautifulSoup4R – all have their own strengths and weaknesses depending on the application they’re used for.
When choosing a scraper it’s important to consider features such as ease of use or scalability; pricing can also be a factor if budget constraints apply. By comparing these different tools side-by-side based on specific needs and use cases one can find the right tool suitable for them that will help extract useful information effectively – both efficiently time wise without compromising quality of results!
