

Java Hashing Mastery: Guide to HashMap and HashSet
Mastering the usage of hashing is a critical part of becoming an efficient Java programmer. Not only can such knowledge be used to create efficient databases and algorithms, but it can also help you develop strong and optimized Java applications. Understanding and mastering hashing can help you gain a much greater understanding of Java programming and will being you one step closer to becoming an expert in the field.
In this hands-on guide, let’s immerse ourselves into the captivating realm of Java hashing. We are going to take a deep dive into two of the most essential and widely-used data structures— HashMap and HashSet—and learn how to maximize their potential.
After we break down each of these structures and discover similarities and differences between them, we’ll discover the practical applications of using HashMap and HashSet in Java projects.
Understanding HashMap
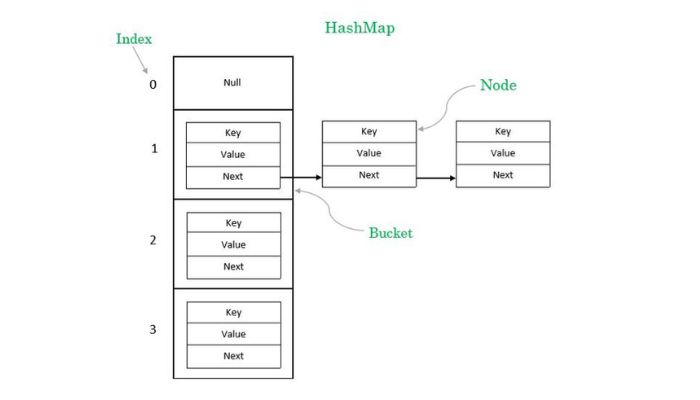
HashMap in Java is a powerful data structure that provides an efficient way to store key-value pairs efficiently. It works on the principles of hashing, which enables it to search and retrieve stored items quickly.
The HashMap implements the Java Map interface and contains key-value pairs. Generally, the keys used by this are instances of Objects while the values may be any type, either a primitive value or an object reference.
Every interface has its different implementation classes and we can easily access these from our code with get/put operations to put elements into it or retrieve them as needed.
Aside from just adding, retrieving, or storing items one can also process the entire collection regarding various sorting orders, etc for which API provided all sorts of options appearing at the signature of each method accepting functionality to form resulting collections the way one expects.
Key-value pairs in HashMap
HashMap consists of an array of buckets, where each bucket stores a key-value pair. It implements the Map interface and therefore allows us to store our Key/Value pairs when explicit order is not required.
Each mapping stored in the HashMap must have a unique key that can be retrieved by its associated value later using getter methods. The keys and values of the Map are both Objects, so they’re almost guaranteed to not clash with one another or disrupt any future set/get request from working properly due to being issue-isolated items held in two distinct but conjoined existences in this system.
Working principle of HashMap
HashMap uses a hashing concept to store objects in the form of key-value pairs. To retrieve values quickly and efficiently, HashMap applies a hashing function to derive an index or hashcode for each stored object.
At retrieval time, this hash code is compared with the stored objects’ hashcodes; only if it matches, then its respective object‘s data is obtained from that particular index.
If collisions occur between different hashcodes derived for different objects already stored at certain indices, extra buckets with same hashed codes are created within Hashmap and further used for speeding up lookup operations.
Hashing functions and collision handling
Hashing functions and collision handling in HashMap involve a set of rules that when applied, map or ‘hash’ data into an array. To look up stored values, the hashing function creates specific indexes by dividing up their inputs according to pre-specified criteria. When collisions occur, where multiple inputs end up mapping to the same solution or index value, techniques such as alter keys and open addressing can be used.
This ensures all data inside the hashtable is accounted for and retrievable using proper keys without overwriting original data points scattered among rehashed items. Handling these collisions efficiently improves performance overall but failures here may result in certain parts of the user’s data remaining ageless or responsible retrieval being painfully slow due to clustering over inefficient solutions.
Common operations and methods in HashMap
Understanding HashMap includes becoming familiar with its common operations and methods. The main operation available in HashMap is put(key, value). This method takes a key-value pair to add it as an entry. An alternative to inserting is the get(key) method, which allows users to retrieve values associated with certain keys.
Users can call remove(key) for removing entries based on their specified key while clear() completely empties the HashMap of all contents.
KeySet() and entrySet() collect respective sets of objects in a Set object containing related information about both keys and corresponding values present inside a Map; this includes size(), which returns an int value indicating total number of entries stored, as well as containsKey/Value functions to check if a given key or value is found in a HashMap.
Exploring HashSet
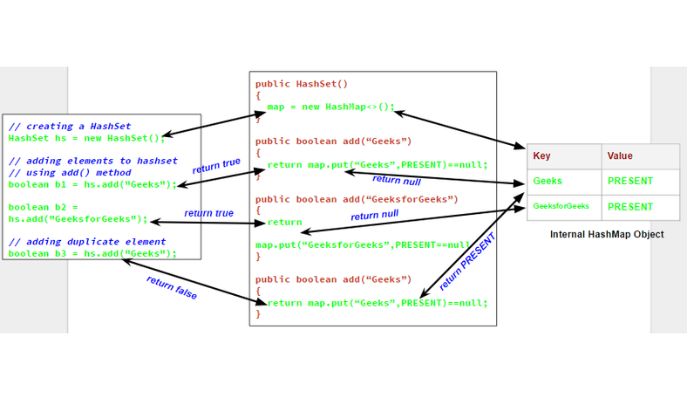
HashSet is an important data structure in Java that is used for storing unique and unordered elements.
Unlike HashMap, which stores key-value pairs, the primary purpose of HashSet is to check for the presence/absence of a specific element in the set. It uses hashing concept behind the scenes to efficiently store and retrieve values from memory which results in increased performance compared to other implementations such as LinkedHashSet or TreeSet.
Unique elements can be added and removed at any time with low computational cost using optimized operations such as add(), remove(), contains() etc. Finally, due to its efficient management of memory usage, it is often preferred when dealing with large datasets where speed matters more than storage space.
Unique elements and set operations
HashSet is a part of the Java Collection Framework and provides unique elements like all other Set implementations. The working principle behind HashSet relies on hashing which stores objects as keys in hash table buckets, preventing them from being duplicated inside the set.
It uses an approach called Equals and HashCode which makes searching faster by creating hash codes that use to keep track of objects in certain groups.
In terms of operations, sets provide more control than just insertion or retrieval because they contain features such as union (adding two existing sets together = AUB) subset (extracting one set from another), intersection (keeping only common objects), etc. These operations help return limited subsets faster whereas traditional loops will be ineffective if applied to often large datasets.
Hashing concept in HashSet
A HashSet is a data structure built on the concept of hashing that helps store and manage unique elements. This structure uses the same hashing method to evaluate keys as that with a HashMap, which means built-in hashCode and equals methods come into play for retrieval, deletion, comparison operations, etc.
Elements in a HashSet are stored internally based upon their hash codes creating buckets at specific sizes to separate them into smaller groups.
If two elements share the exact same code then it leads to a collision resolution process relying heavily on processor time, outbound performance & memory utilized during execution streamlining search times needed before retrieving an element from its respective block allocated by the set variable’s configured specifics.
Performance and use cases of HashSet
HashSet is a powerful data structure for storing unique elements when optimization and memory management are top priorities. When applied efficiently, HashSet can offer superior runtime performance than other similar collections if the dataset follows certain characteristics, such as non-ordered collections including no duplicate items.
It has an efficient storage operation, using hashing technologies to store and retrieve elements, resulting in near constant-time operations over datasets of any size; however overall performance depends on its implementation.
Ideal use cases include fast search facilities or sets intersect operations due to being able to compare two large sets very quickly as long as no additional iteration is needed.
Key methods and operations in HashSet
HashSet is a specialized implementation of the Set interface in Java that uses hashing construction algorithms which allow for faster insertion and retrieval when compared to other data structures. It works by removing duplicates and expanding or contracting its capacity automatically according to the load factor.
Key methods and operations in HashSet include adding elements, retrieving elements, iteration over elements, manipulating set elements such as union and the intersection of two sets, comparing for subset relation between hash indices etc.
Basic Operation using combine two distinct sets or contract into a single unordered planet containing unique records. This makes it possible to perform efficient sorting among different datasets when new hires come along very often with sorted collections.
Practical Implementation
Creating and initializing HashMap and HashSet
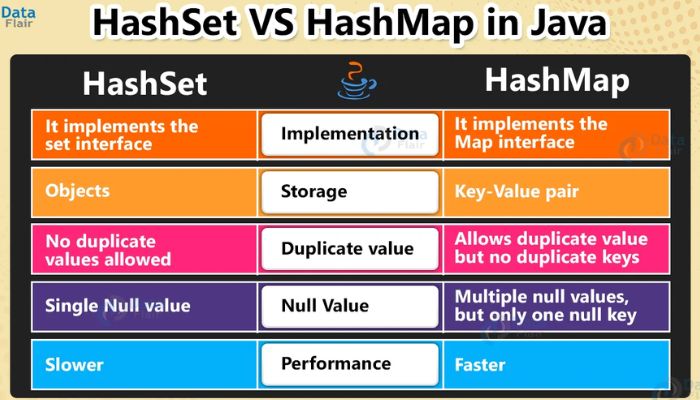
When it comes to working with HashMap and HashSet in Java, one of the most important skills is generating and initializing them. This involves creating a new instance, specifying initial capacity parameters like key-value pairs or sizes, identifying hash functions for custom objects as keys, and loading factors to consider when working with frames.
Maintaining thread safety is also important; concurrent modifications of elements should be done within proper methods and environments. Failing to pay attention to these details can easily cause exceptions in runtime or decreased performance issues so following the guidelines carefully helps in improving mastery over hashing functionalities.
Adding, retrieving, and removing elements
Adding, retrieving, and removing elements in HashMap and HashSet are essential methods for working with both data structures. When adding an element to the Map, a hashing process is used to generate an index key from much longer values such as strings or custom objects before storing a key-value pair in memory.
Using put()can be the retrieval of the previously stored value can be done by calling get(), which uses identical logic as when the original key was added.
Lastly, if one wishes to remove an existing key-value association from a container, one can do so through the use of the dedicated remove() function. As always certain performance considerations should be taken note of when planning out one’s codebase.
Iterating over elements in HashMap and HashSet
Iterating over the elements of a HashMap or HashSet is relatively simple, using various collection framework methods.
To loop through each individual value for HashMap, one must iterate through “entries” in the set; these entries are essentially key-value mappings within the hashmap which can be circulated with entrySet() and iterator(). For high-performance looping thorough HashseT values, enhanced for-each traversal as well as iterator() techniques are available.
Custom enhancements to achieve improved performance by factors such as parallelizing iteration can also greatly improve speed.
Conclusion
HashMap and HashSet are essential data structures to know when working with Java. With proper understanding, they allow a developer to take advantage of their key performance benefits while avoiding the complexities related to hash collisions.
Overall, an individual should understand how hashing works in Java, explore the characteristics of HashMap and HashSet, including methods and operations within them, design implementations for them, as well as handle memory compliances such as garbage collection intelligently before reaping the maximum benefits from these finite collections.
